
Hadoop 集群快速搭建指南(VMware 克隆版)
环境规划
| 主机名 | IP地址 | 角色 |
|---|---|---|
| master | 192.168.157.137 | NameNode, ResourceManager |
| slave1 | 192.168.157.138 | DataNode, NodeManager |
| slave2 | 192.168.157.139 | DataNode, NodeManager |
第一部分:克隆前配置(在第一台虚拟机上完成)
1. 关闭防火墙和 SELinux
systemctl stop firewalld && systemctl disable firewalld && sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
2. 配置 hosts
cat >> /etc/hosts << EOF
192.168.157.137 master
192.168.157.138 slave1
192.168.157.139 slave2
EOF
3. 配置阿里云 yum 源(CentOS 7)
rm -f /etc/yum.repos.d/CentOS-Base.repo && cat > /etc/yum.repos.d/CentOS-Base.repo << 'EOF'
[base]
name=CentOS-7.9.2009 - Base - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos-vault/7.9.2009/os/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-7
[updates]
name=CentOS-7.9.2009 - Updates - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos-vault/7.9.2009/updates/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-7
[extras]
name=CentOS-7.9.2009 - Extras - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos-vault/7.9.2009/extras/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-7
EOF
yum clean all && yum makecache && yum install -y lrzsz
4. 下载 JDK 和 Hadoop
mkdir -p /opt/software && cd /opt/software
# 下载 JDK
wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz
# 下载 Hadoop
wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz

5. 安装 JDK
mkdir -p /usr/local/java && tar -zxvf /opt/software/jdk-8u202-linux-x64.tar.gz -C /usr/local/java/ && ls /usr/local/java/
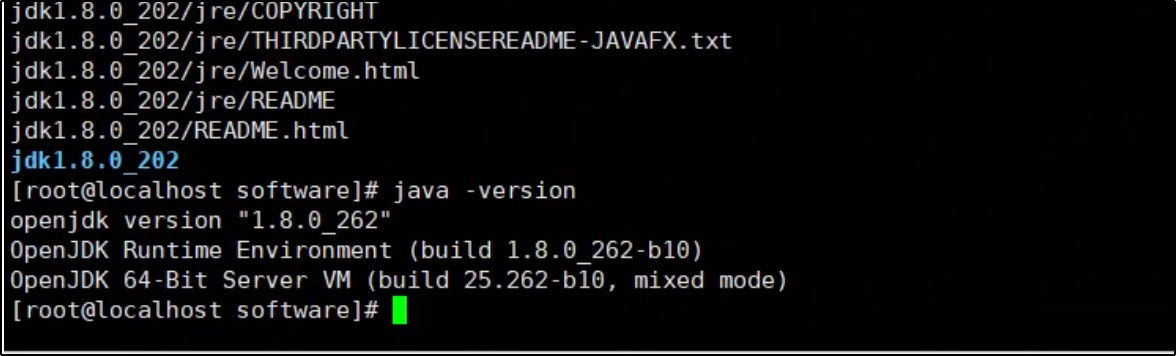
6. 安装 Hadoop
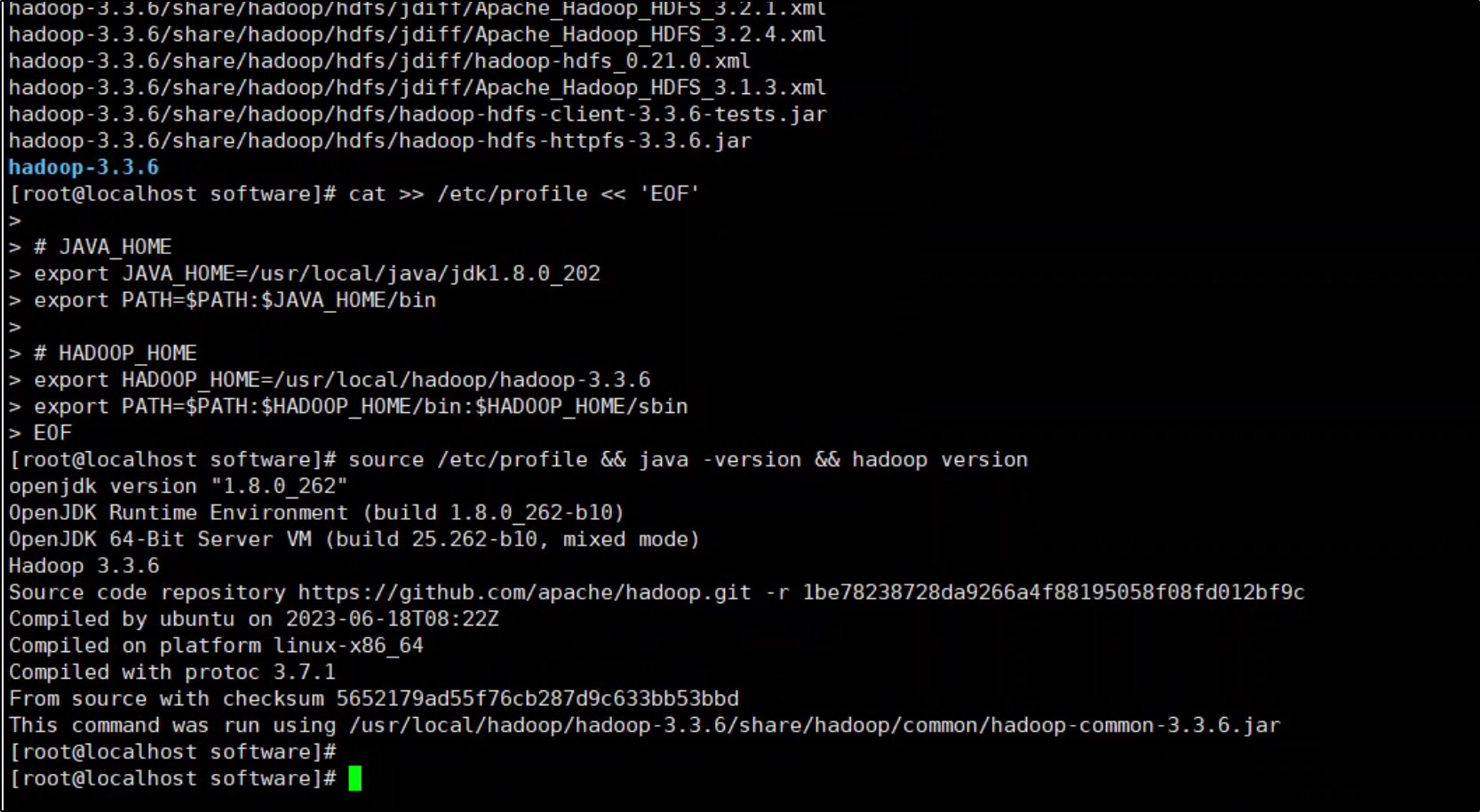
mkdir -p /usr/local/hadoop && tar -zxvf /opt/software/hadoop-3.3.6.tar.gz -C /usr/local/hadoop/ && ls /usr/local/hadoop/
cat >> /etc/profile << 'EOF'
# JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_202
export PATH=$PATH:$JAVA_HOME/bin
# HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
EOF
source /etc/profile && java -version && hadoop version
8. 配置 Hadoop 所有配置文件
cd $HADOOP_HOME/etc/hadoop
cat >> hadoop-env.sh << 'EOF'
export JAVA_HOME=/usr/local/java/jdk1.8.0_202
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
EOF
cat > core-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-3.3.6/tmp</value>
</property>
</configuration>
EOF
cat > hdfs-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hadoop-3.3.6/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop-3.3.6/hdfs/data</value>
</property>
</configuration>
EOF
cat > mapred-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
EOF
cat > yarn-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_HOME/etc/hadoop:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/lib/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/hdfs/lib/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/share/hadoop/yarn/lib/*</value>
</property>
</configuration>
EOF
cat > workers << 'EOF'
slave1
slave2
EOF
mkdir -p $HADOOP_HOME/tmp $HADOOP_HOME/hdfs/name $HADOOP_HOME/hdfs/data
echo " Hadoop 配置完成!"
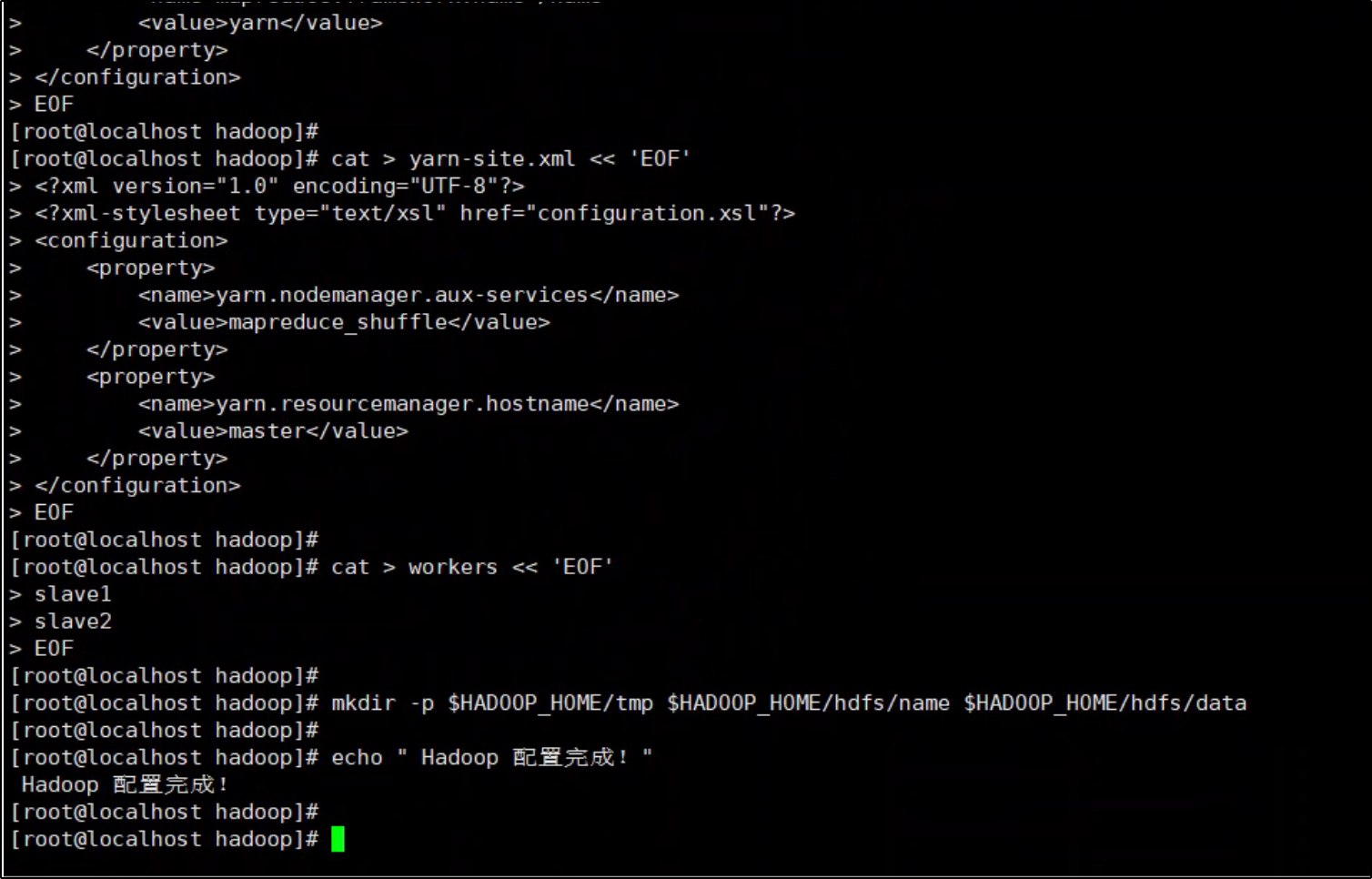
9. 关机准备克隆
shutdown -h now
第二部分:VMware 克隆
- 在 VMware 中右键虚拟机 → 管理 → 克隆
- 选择"创建完整克隆"
- 分别命名为
slave1和slave2
第三部分:克隆后配置(三台机器都已启动)
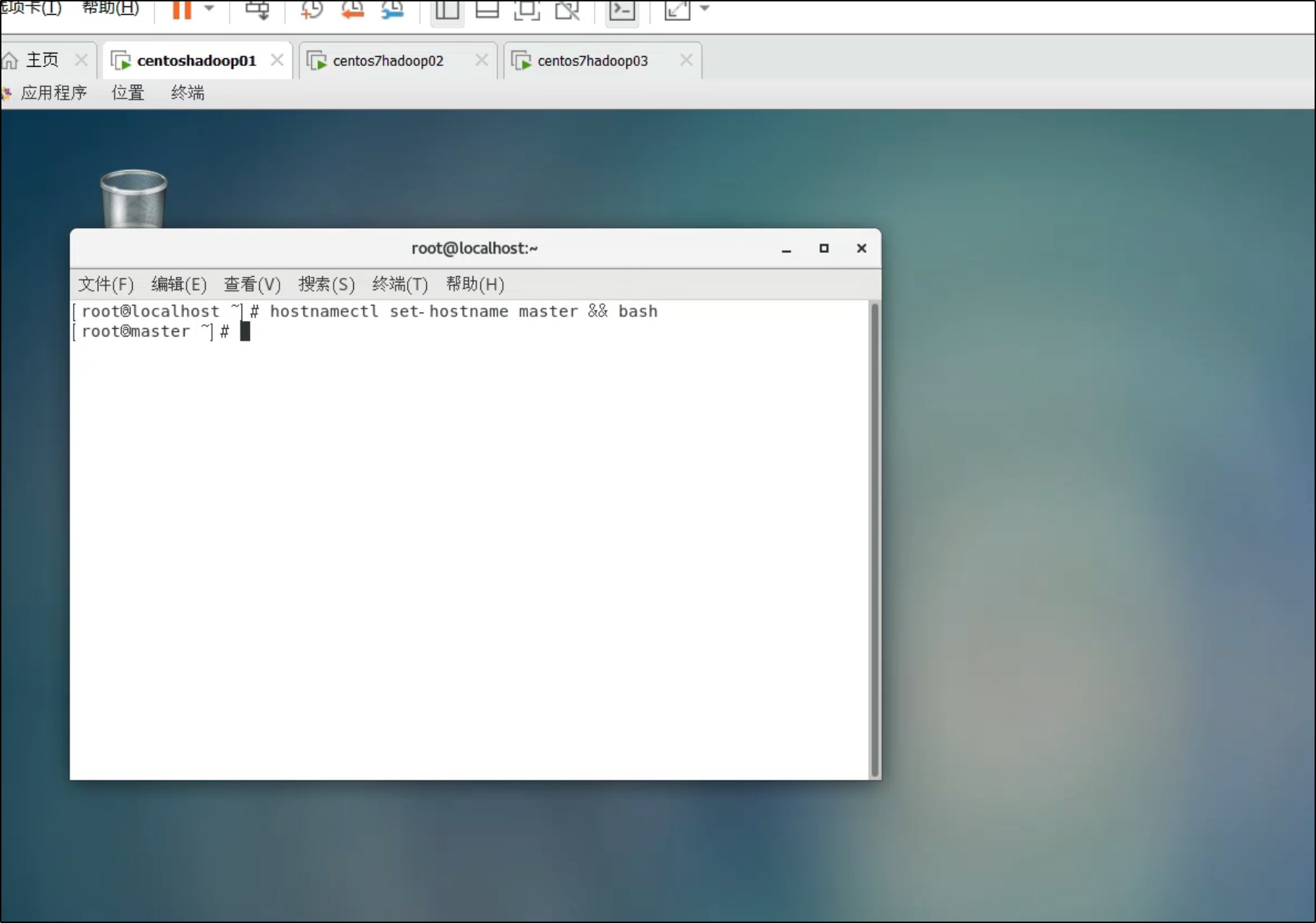
1. 修改主机名
第一台 (192.168.157.137):
hostnamectl set-hostname master && bash
第二台 (192.168.157.138):
hostnamectl set-hostname slave1 && bash
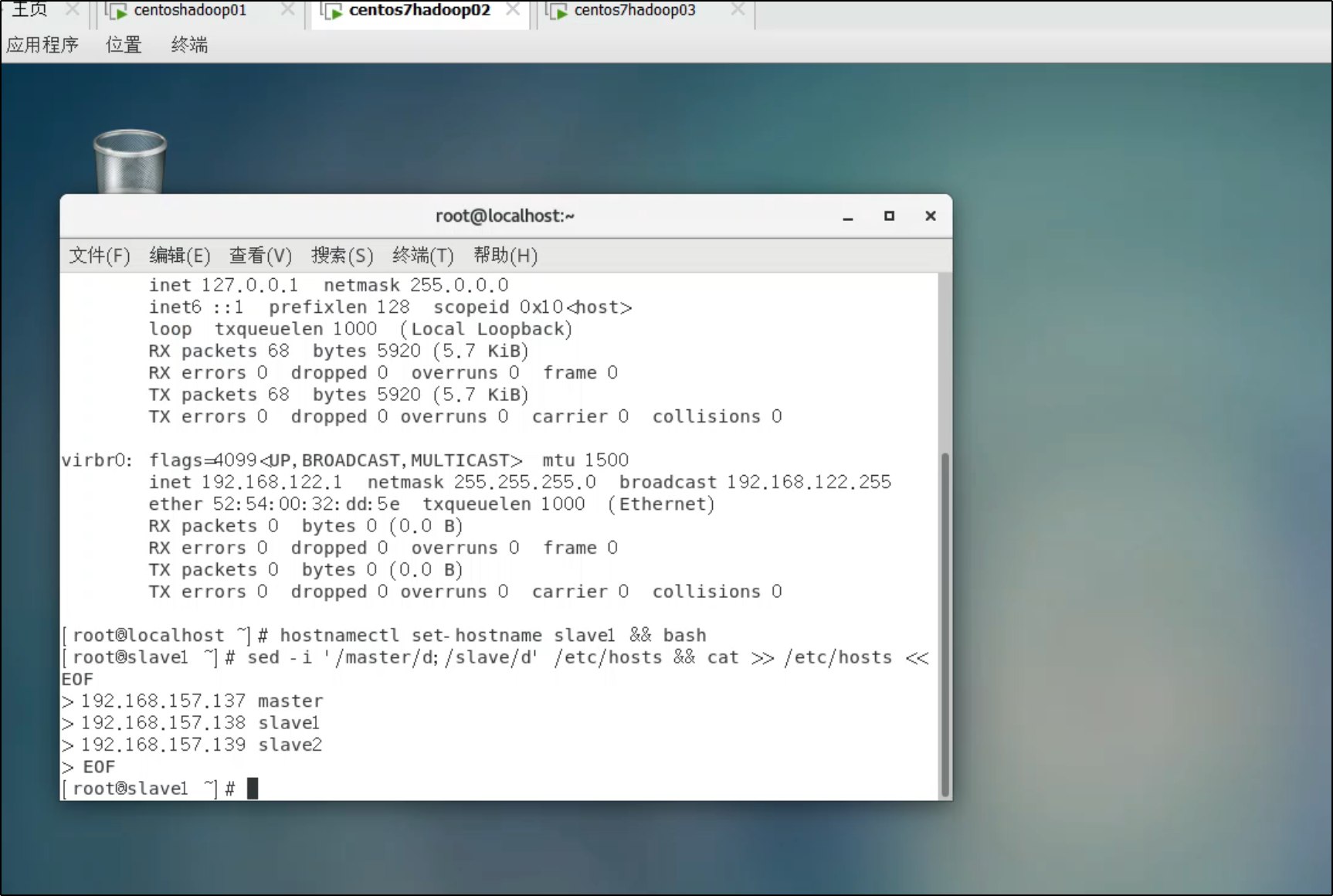
第三台 (192.168.157.139):
hostnamectl set-hostname slave2 && bash
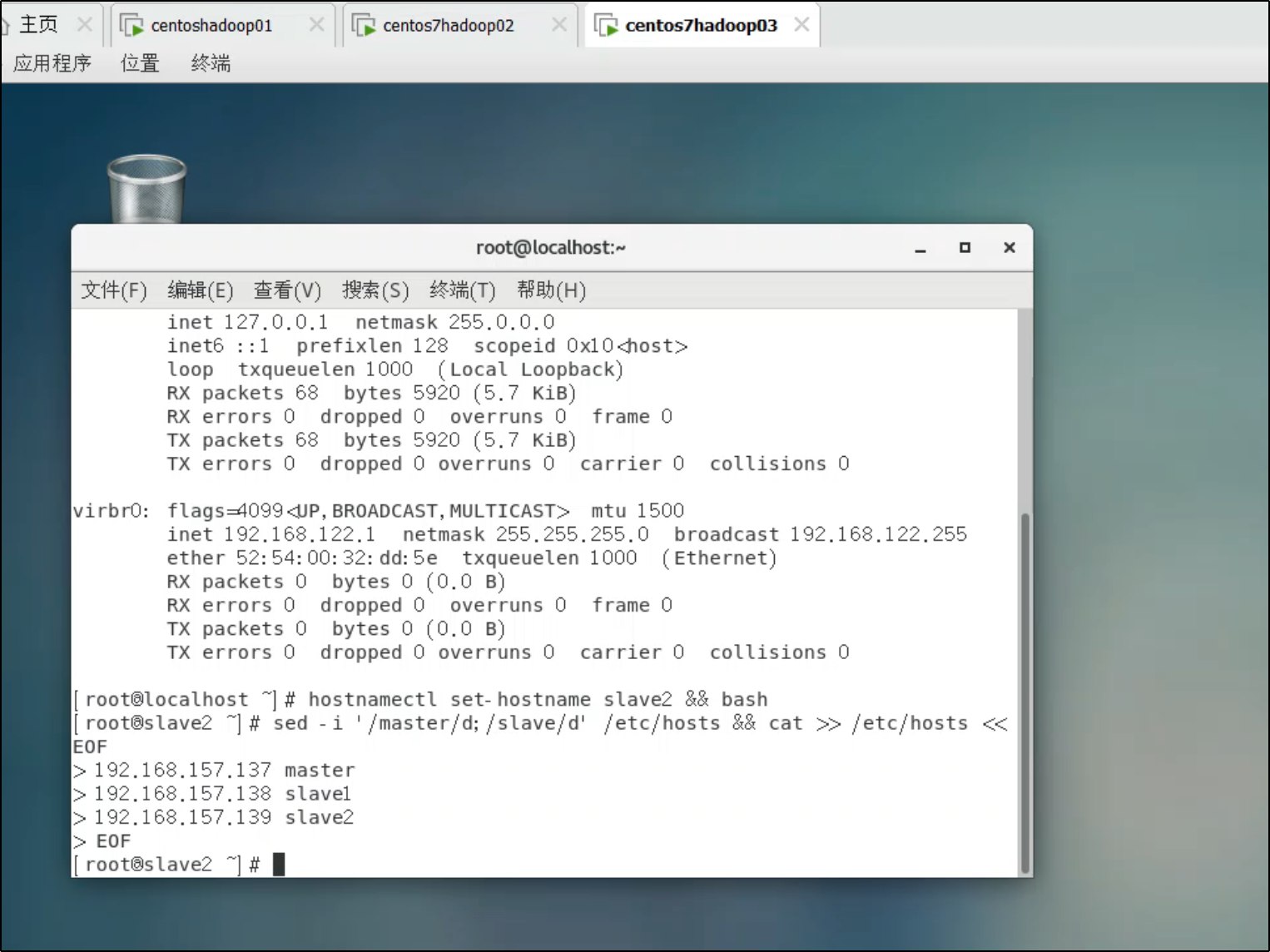
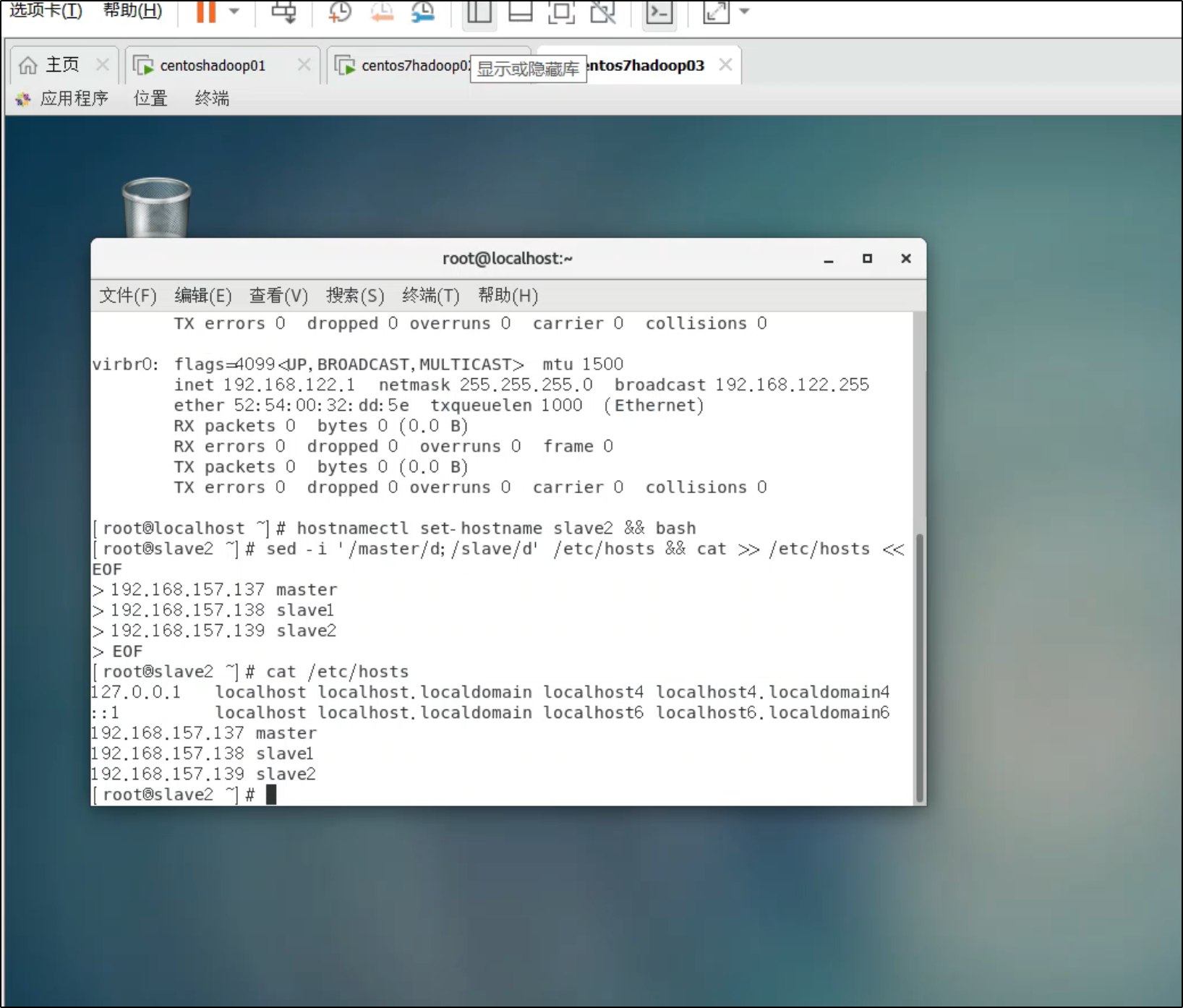
2. 更新 hosts 文件(三台机器都执行)
由于克隆后 IP 已自动分配,需要更新 hosts:
sed -i '/master/d;/slave/d' /etc/hosts && cat >> /etc/hosts << EOF
192.168.157.137 master
192.168.157.138 slave1
192.168.157.139 slave2
EOF
验证:
cat /etc/hosts
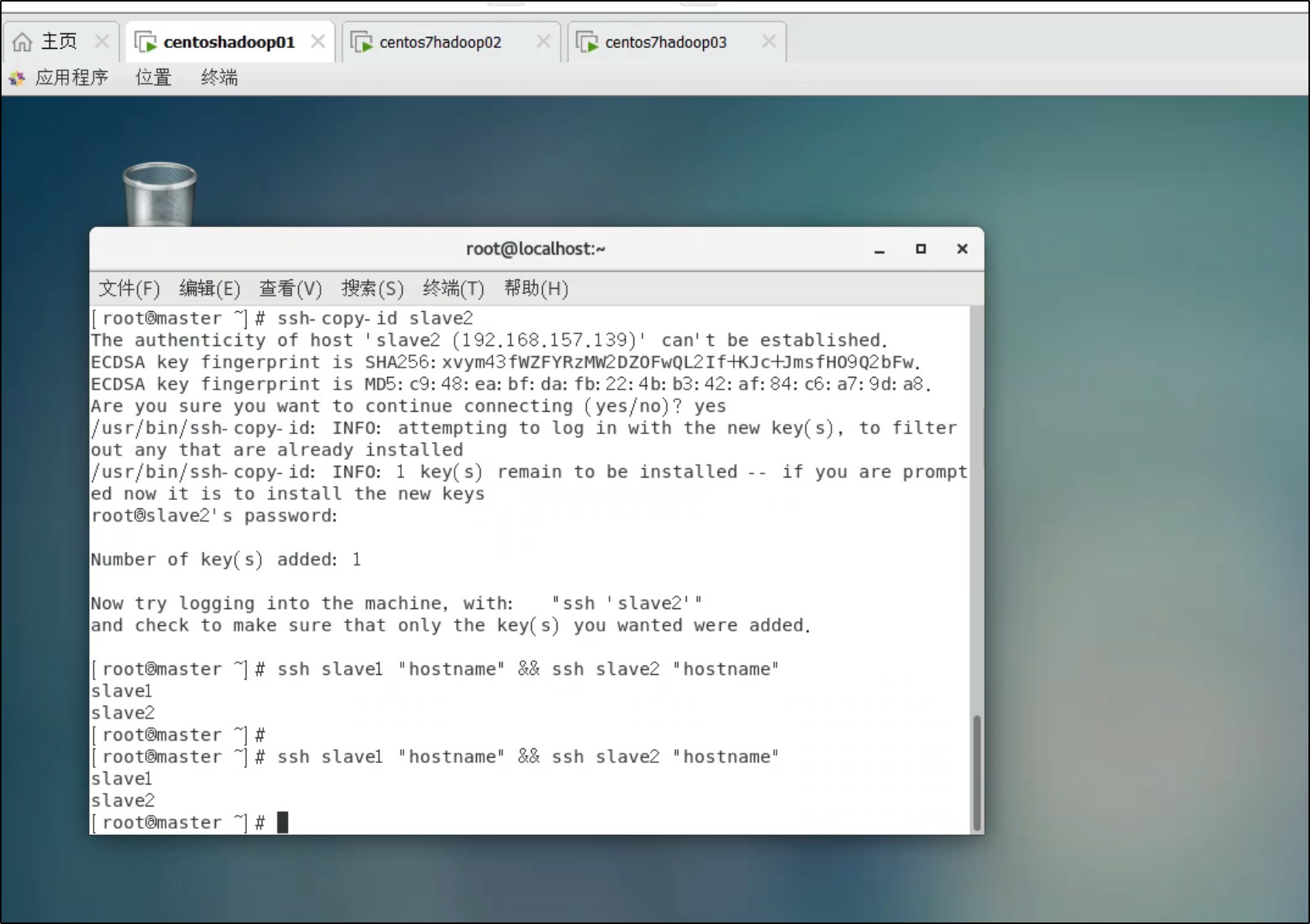
3. 配置 SSH 免密登录(仅在 master 执行)
ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
验证:
ssh slave1 "hostname" && ssh slave2 "hostname"
第四部分:启动集群
1. 格式化 HDFS(仅首次,仅在 master)
hdfs namenode -format
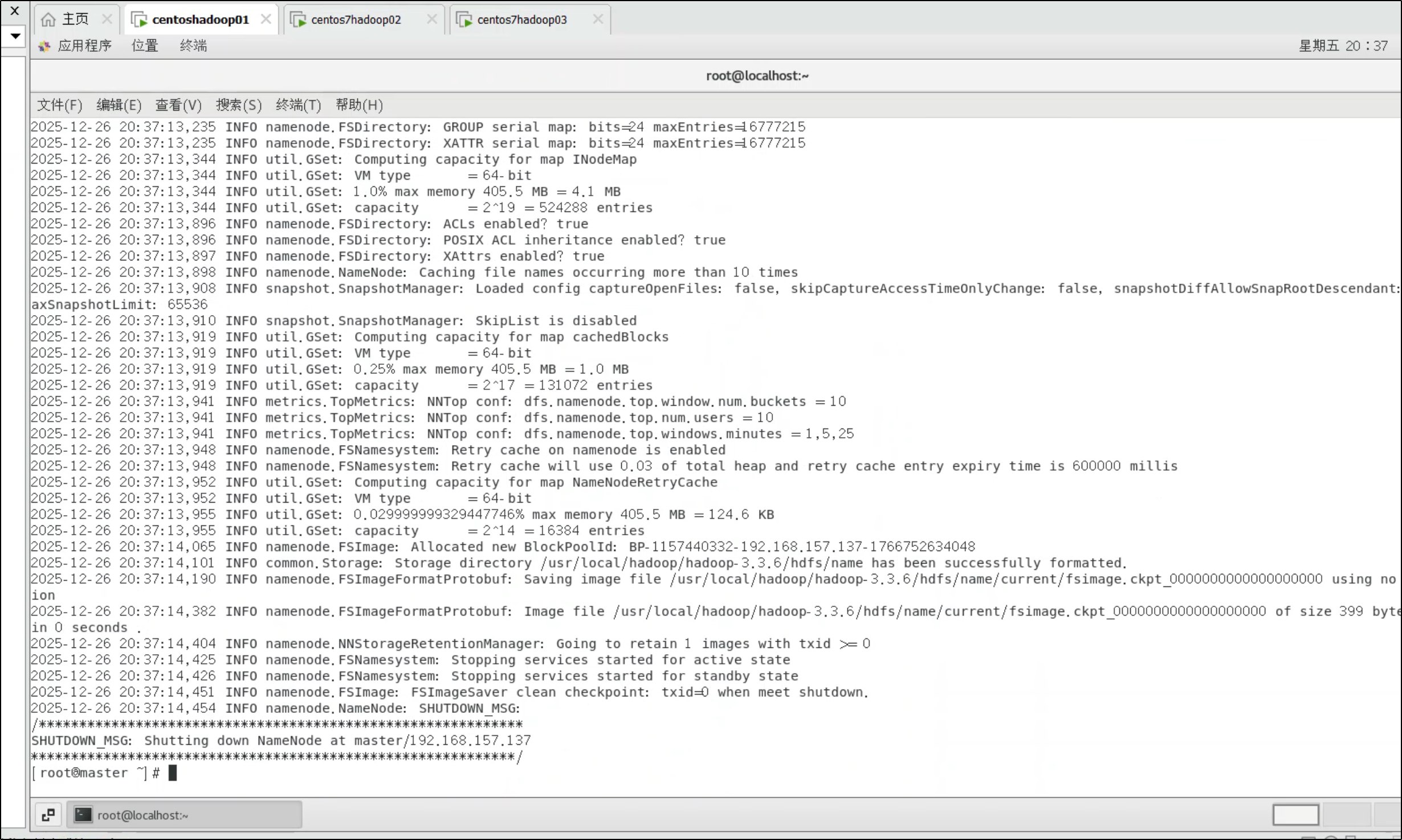
看到 successfully formatted 表示成功。
2. 启动 HDFS 和 YARN
start-dfs.sh && start-yarn.sh
3. 验证集群
在 master 执行:
jps
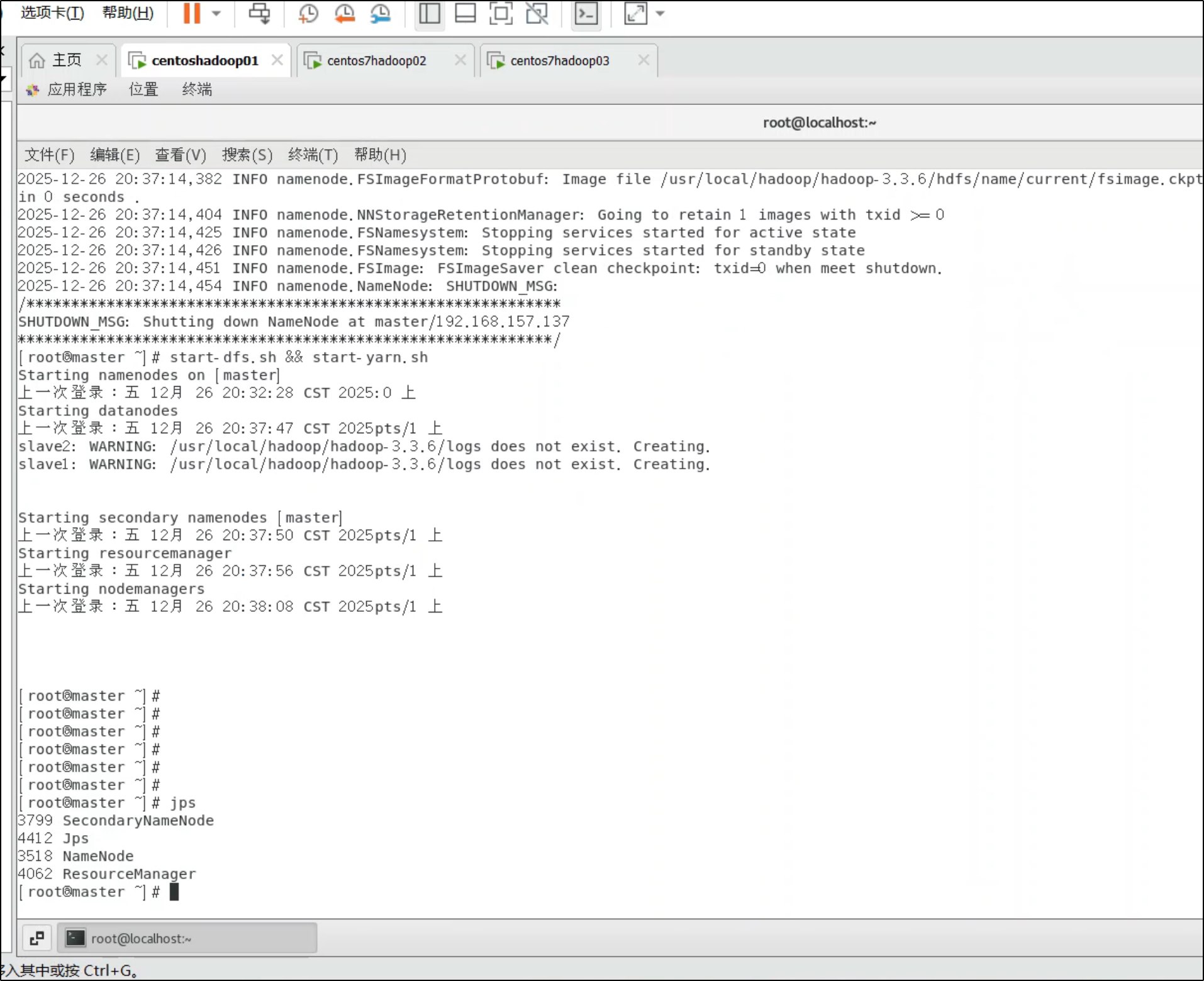
应显示:
- NameNode
- SecondaryNameNode
- ResourceManager
在 slave1/slave2 执行:
jps
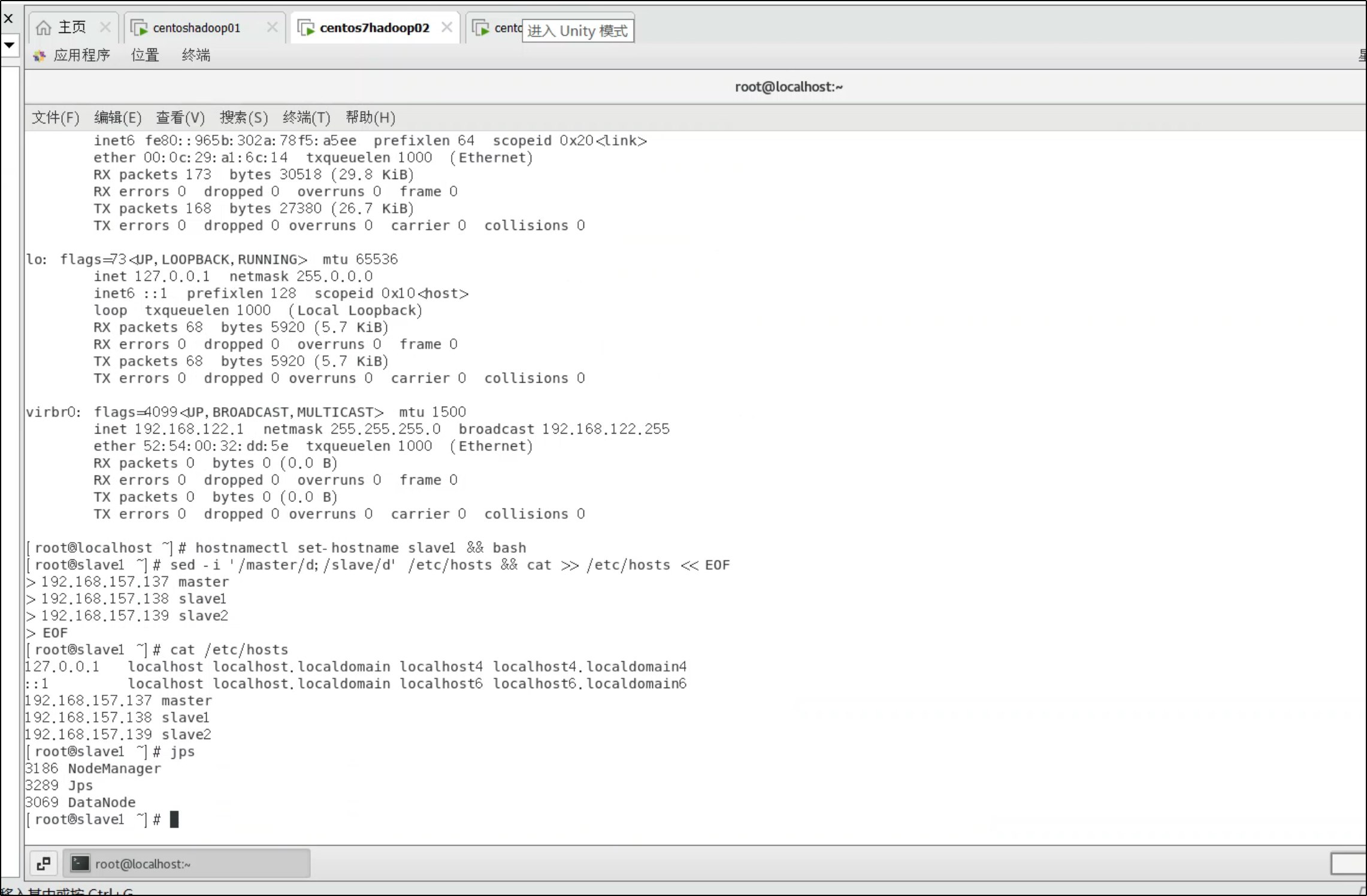
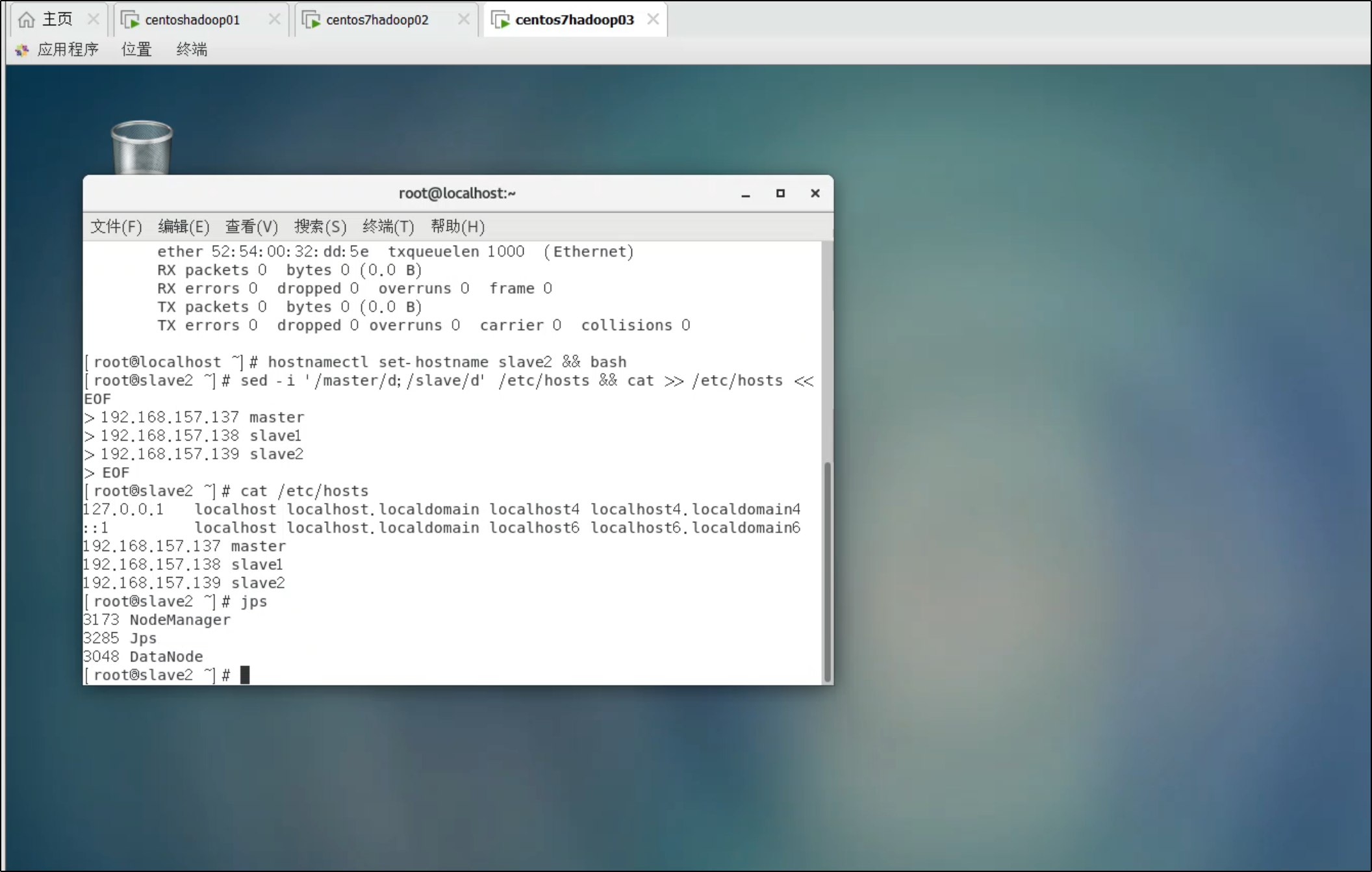
应显示:
- DataNode
- NodeManager
4. 查看集群状态
hdfs dfsadmin -report
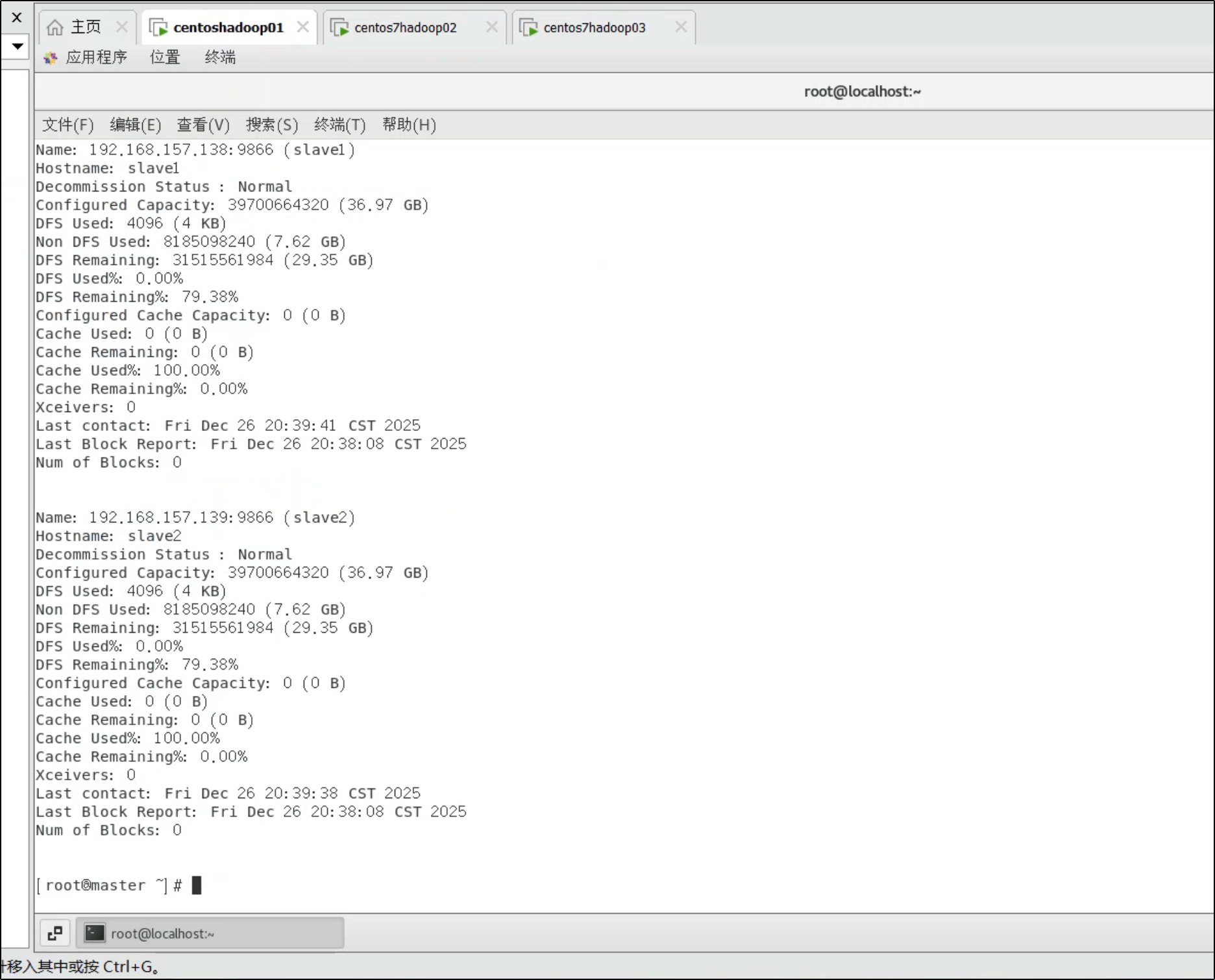
5. Web 界面
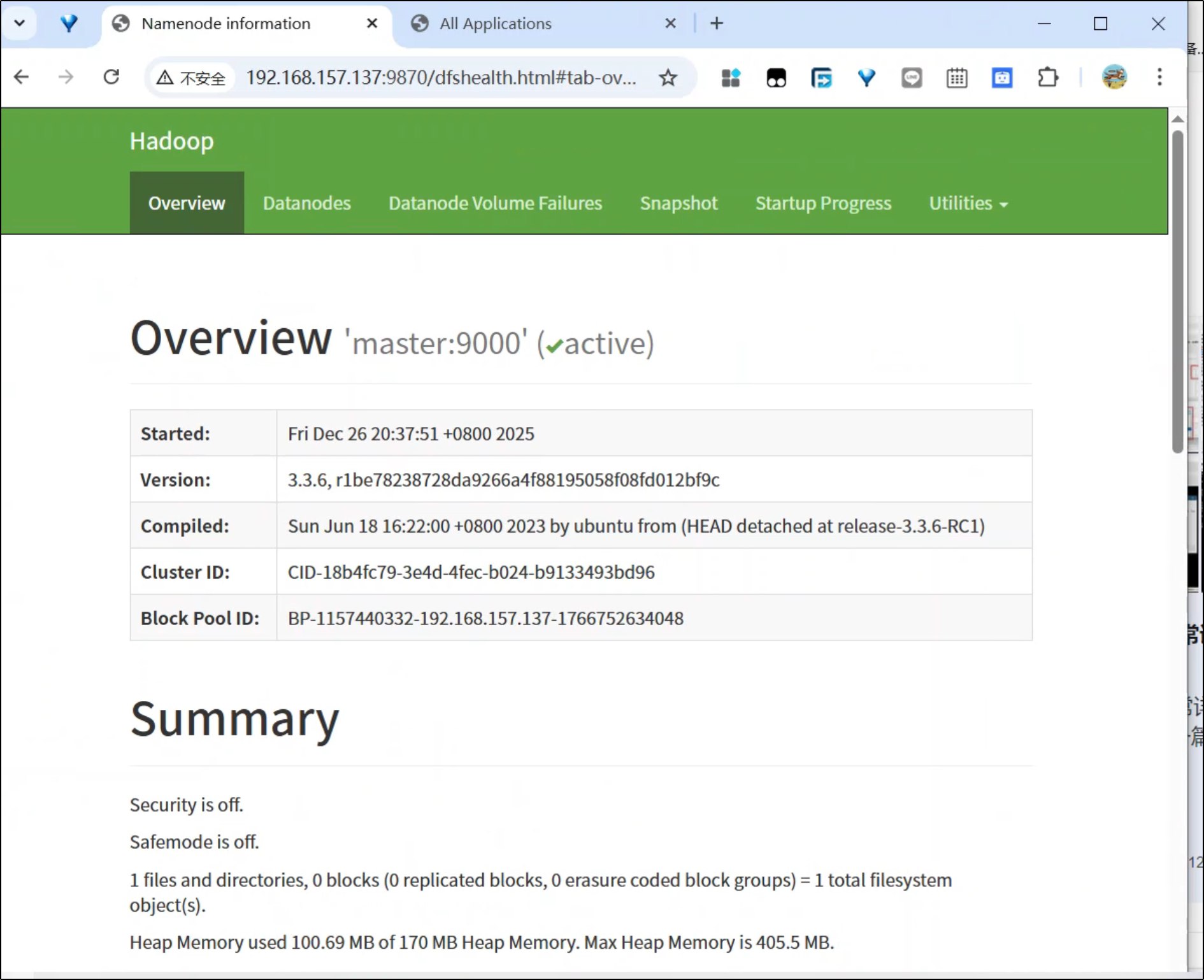
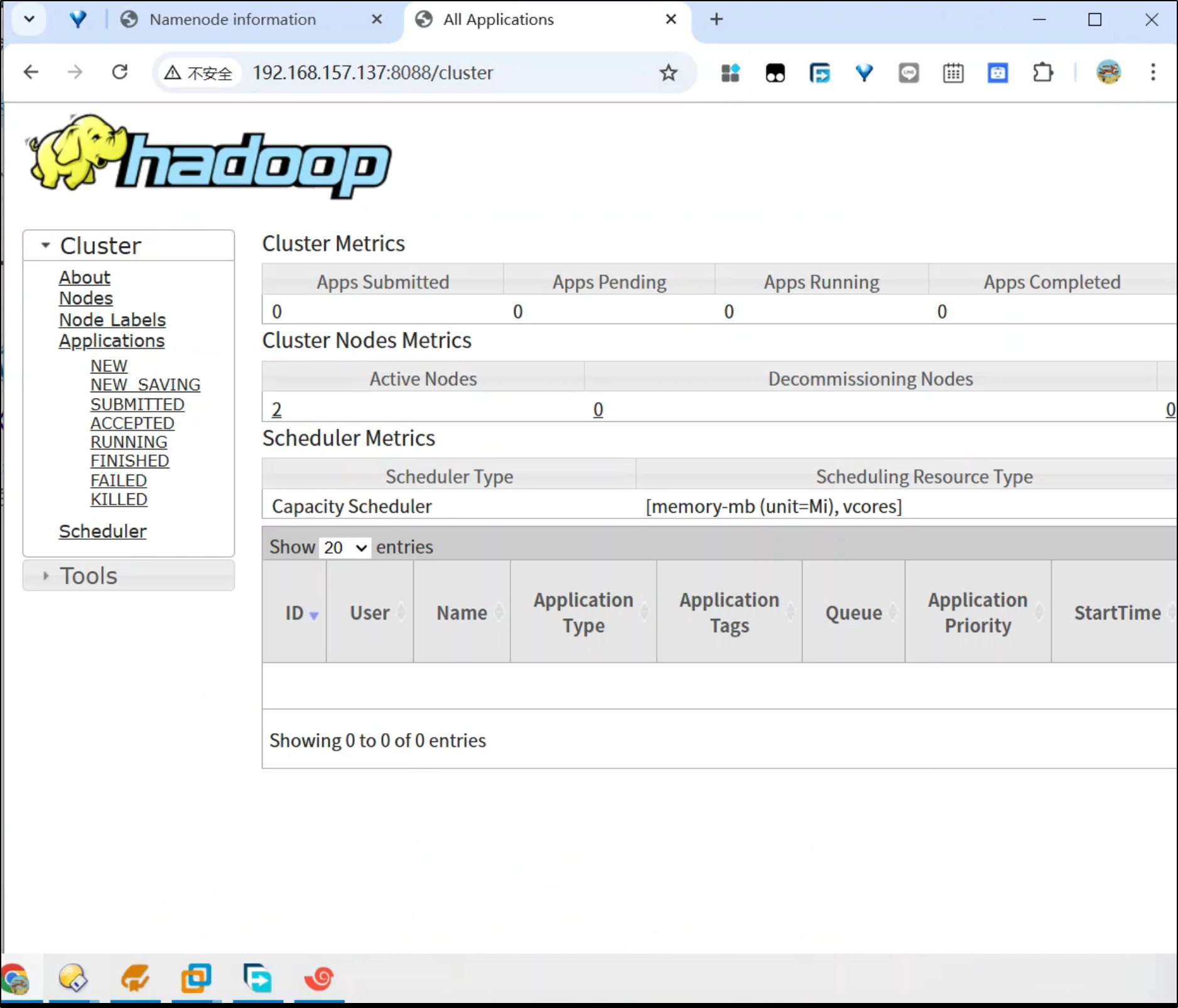
第五部分:测试集群
hdfs dfs -mkdir -p /user/root/input
hdfs dfs -put /etc/profile /user/root/input/
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/root/input /user/root/output
hdfs dfs -cat /user/root/output/*
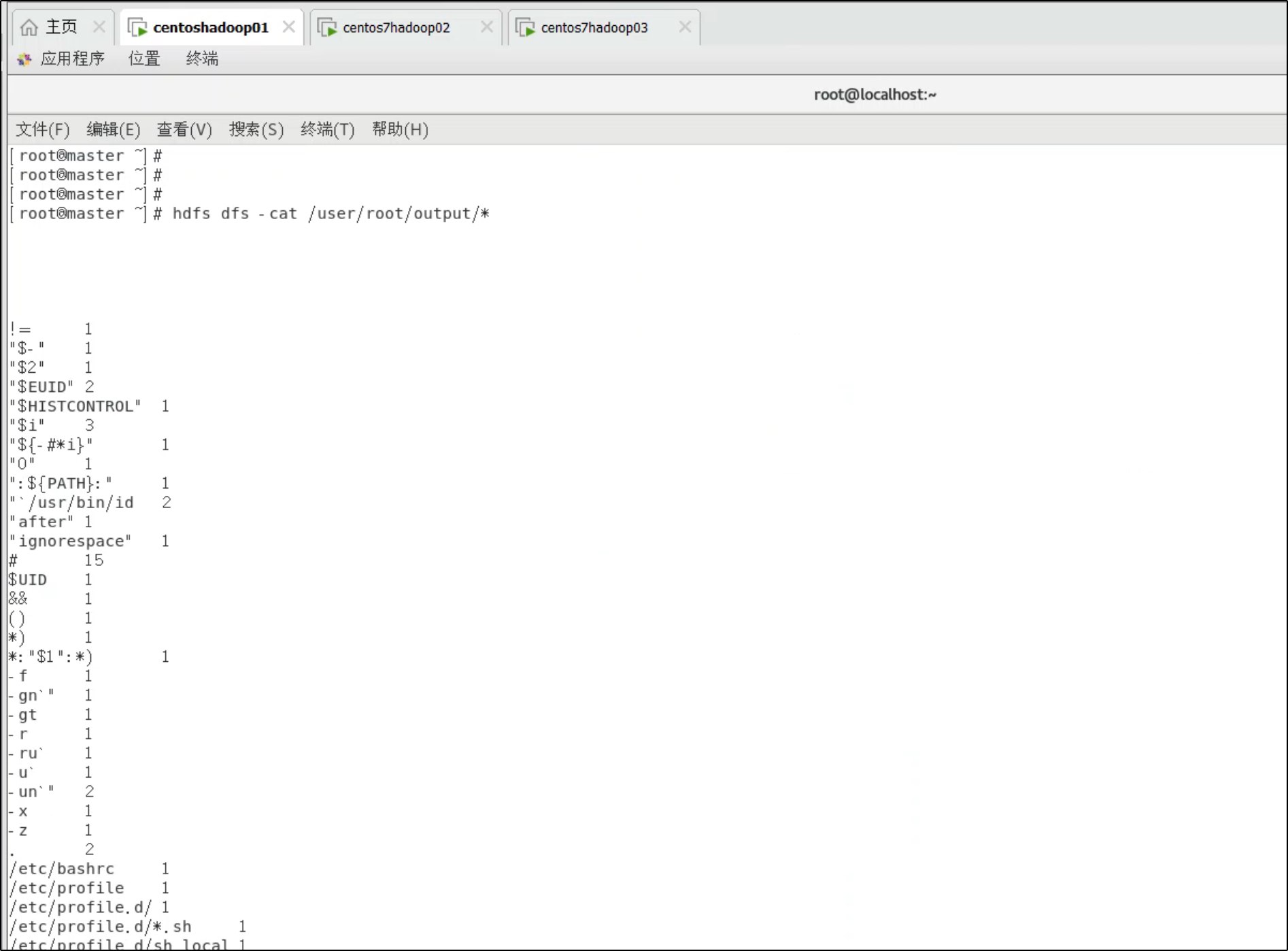
常用命令
| 命令 | 说明 |
|---|---|
start-dfs.sh |
启动 HDFS |
stop-dfs.sh |
停止 HDFS |
start-yarn.sh |
启动 YARN |
stop-yarn.sh |
停止 YARN |
start-all.sh |
启动所有 |
stop-all.sh |
停止所有 |
jps |
查看 Java 进程 |
hdfs dfsadmin -report |
查看集群状态 |
常见问题
1. DataNode 无法启动
rm -rf $HADOOP_HOME/hdfs/data/* $HADOOP_HOME/tmp/*
hdfs namenode -format
start-dfs.sh
2. SSH 连接失败
- 检查防火墙:
systemctl status firewalld - 检查 hosts:
cat /etc/hosts - 重新配置免密:
ssh-copy-id slave1
3. 网络不通
ping slave1
ping slave2
4. MapReduce 报错"找不到或无法加载主类 MRAppMaster"
这是 classpath 配置问题,需要修改 mapred-site.xml 和 yarn-site.xml:
cd $HADOOP_HOME/etc/hadoop
cat > mapred-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
EOF
cat > yarn-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_HOME/etc/hadoop:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/common/lib/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/hdfs/lib/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/share/hadoop/yarn/lib/*</value>
</property>
</configuration>
EOF
修改后需要同步到所有节点并重启 YARN:
scp $HADOOP_HOME/etc/hadoop/mapred-site.xml slave1:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/mapred-site.xml slave2:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/yarn-site.xml slave1:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/yarn-site.xml slave2:$HADOOP_HOME/etc/hadoop/
stop-yarn.sh && start-yarn.sh
